Survival of The Fittest CS 175: Project in AI (in Minecraft)
A Malmo Project for CompSci 175 at UC Irvine
Project Summary
The Survival of the Fittest Project (Our CompSci 175 Project) aims to utilize the knowledge regarding machine learnings and intelligence system to build an agent who can survive under the wave of attacking from mobs in Minecraft Project Malmo. In the initial proposal, the goal of the project aimed to “train the agent with… Zombie Pigman, Wither, Blaze, etc.” and allow the agent to “utilize the terrain to its advantage when given a more complex map.” However, we are facing some feasibilities on current stage. We intend to construct adequate infrastructures (Agent Deep Q Network Method or Agent Neuroevolution of Augmenting Topologies Method, Environment, etc.) to train the agent and even let it fights with all mobs in all terrain. The key objective is to train an agent to survive in a complex environment as long as possible. Longevity is the goal.
At this stage, the current objective is to establish one of the methods (either Deep Q Network or Neuroevolution of Augmenting Topologies) and train the agent to fight with one Zombie in a limited pure environment, which is demonstrated in our video(s). The Deep Q Network has been utilized and constructed in our agent class. It allows the agent to learn the ideal approach in different situations. The environment is limited to a 21-by-21 cage without any obstacles. The team has added a random environment generator to construct more complex environment, but due to the damper of time, we have not attempted to train the agent in such environment.
For the final report, our team aims to utilize the environment generator to prepare/train the agent in a more sophisticated manner. We would also improve the performance of our existing Deep Q Network, and possibly keep attempting to build an agent with the Neuroevolution of Augmenting Topologies. The complexity (toughness) of enemies would also be increased by that time. We expect the agent can not only survive under constant attacking by Zonbie, but also deal with various of attacks from Zombie Pigman, Wither, and Blaze.
Approach
Environment Representation / Actions / Reward

For now, our agent tries to survive inside a 21-by-21 cage with one enemy shown as above. The environment our agent can see is also a 21-by-21 matrix where the agent itself is located at the center of the matrix (matrix[10][10]) at the very beginning.
To simplify the state, we use 1 to represent enemy, 0 to represent both the agent and the air, and -1 to represent block. For each state, there are four associated actions: left (represented by 1), right (represented by 2), up (represented by 4) and down (represented by 8).
Reward for each state and action depends on three criteria: angen’s current health, distance between agent and closest enmey (only one enemy for now), distance between agent and cloest wall. The agent will be rewarded less if it’s attaced by enemy and lose health (-0.5). The agent will have points deducted (-0.2) if the distance between the agent and the cloeset enemy is less than 2.0 because it is probaly within the enemy’s attack range. Also, the distance between the agent and the cloest wall is crucial as well (-0.1 if the distance is less than 1.0), because the closer the agent and the wall is, the more likely the agent is attacked by the enemy.
Of course, the agent will be rewarded if it is able to make a move that increase the distance between enemy (+0.3) or distance between wall (+0.2) and some extra rewards if it is able to keep a long distance for a period of time.
Notes: the total reward is within the range of (-1, +1) becasue we use tanh as the activation function.
Algorithm
We are using Deep Q Network algorithm to train our agent. Here is a good graphic representation of the training process, excpet we do not need to convolute the game state since we already represent the state with matrix:
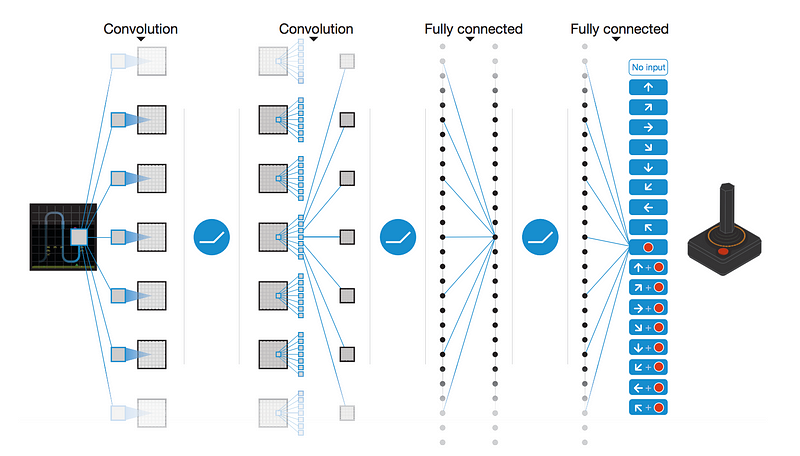
The basic idea of Deep Q Network is similar to that of the Q-Learning where we have a reward (Q-Value) associated with a state and each of its corresponding action(s). Then we select the action which possesses the maximum Q-Value among all options.
However, Q Learning is not a feasible approach in our case, since the state is too large and complicated. With a map size of 21 * 21 and three possible entities on each block of map, our program will require gigabytes of space to store a Q-Table (3^441 possible states and 4 actions for each state).
Hence, alternatively, we decided to use Deep Q Network, in which the Q-Function is represented by a Neural Network. It takes the state (matrix) and four actions as inputs, and it outputs the Q-Value for each possible action. Fianally, the agent can pick the action with the most optimized predicted Q-Value and follow it.
For our implementation of Neural Network, we have one input layer with 442 nodes (21 * 21 matrix that represent the current state and 1 value that represent the action), three hidden layers and a output layer with one node. We use hyperbolic tangent as the activation function so the predicted output will be within the range of (-1, 1).
What truly seperate Deep Q Network with other reinforcemnet learning algorithm is its ability to “replay”. The pseudocode of replay function is shown as follow:

As shown in the pseudocode shown above, the experience <previous_state, previous_action, reward, current_state> is stored each time the agent made a move. To implement this function, we use a list (will probably change to deque in the future) to memory the past experience. Once an episode is ended, a small batch of random experience is retrieved from the list and we use stochastic gradient descent to update the weights of Neutral Network based on these experiences. This method can not only help our agent avoiding local minium but also improve and stable the agent’s performance since the reward for each state is discrete instead of continuous.
Evaluation
For now, we use the Mean Square Error between the actual Q-Value and the predicted Q-Value to evaluate our agent’s performance. Here’s an MSE for our first 300 episode.
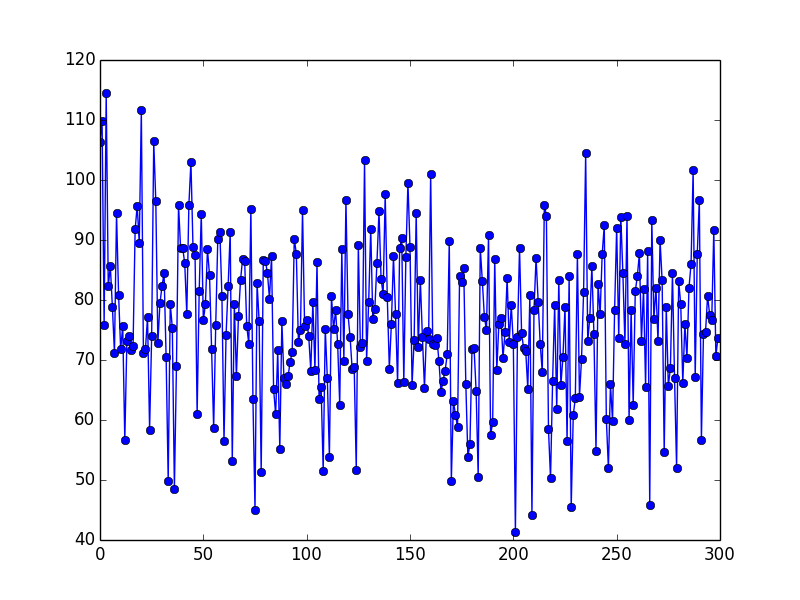
Even though the total survival time for our agent is gradually improving (from the 20s to 30s after 300 episode). The MSE for during this period does not decrease a lot as we expected. One reason might be that the way we assign a reward to each state and its associated action is too complicated for the Neural Network to learn and approximate. The other reason might be that the learning rate is too small (0.01 as we generated this picture) so that we can hardly see significant improvements within 300 episode. Therefore, finding a better way to assign reward and a more straightforward evaluation method is a major focus before the final.
Remaining Goals and Challenges
As briefly mentioned in the project summary, our ultimate objective is still to develop an agent that can survive attacks from different mobs in a complex environment, with a variable amount of enemies. We hope to combine what we have learned in classes CompSci 171, CompSci 175, CompSci 177, CompSci 178 and various online resources to code such agent.
In the next couple weeks, regarding the testing environment, we are first going to introduce the complex environment generator into the testing process and increase the amount of Zombie from one to a larger number. Then we would also try to adopt different kind of mobs that can challenge our agent in a variety of circumstances.
The core improvement needed is to seek a more efficient way to train the Deep Q Network to increase the agent’s survival time (in seconds). As shown in the video, we are making progress in allowing the agent to survive longer (from a few seconds to 20 seconds, but unstable). However, due to the current limitations, we have constrained our goal to be only 30 seconds, and we have not produced solid result yet – a situation when an agent can always survive up to 30 seconds. Improving the survival time would be one of the paramount targets of our project.
Another major challenge is that we should explore a more rational way to evaluate a state. For a given state, the Q-Values predicted for four possible actions are quite similar, which is not what we expect because it sometimes could conduct actions unwisely (i.e., the agent sometimes walks straight toward the Zombie and get hurts actively). Under a better logistic, we believe that the Q-Values for one or two actions should be outperformed to the other options so that the agent would know which action(s) is/are the best in its current state.
Beside the Deep Q Network, we would also keep trying to build a Neuroevolution of Augmenting Topologies solution for training the agent. The performance of Neuroevolution of Augmenting Topologies shown in our research is promising. Although it is a difficult mission, we would still try to produce a better alternative tool than our existing Deep Q Network. It could be an improved version of our current Deep Q-Learning, or it could be a Neuroevolution of Augmenting Topologies.